
AI – et tveægget sværd indenfor cybersikkerhed
Den data, du deler med store sprogmodeller som ChatGPT, Gemini og Claude, kan være følsom, hvis den kommer i de forkerte hænder. Samtidig er AI blevet et redskab, der både kan beskytte mod svindel og misbruges til digitale angreb.
Af Michaela Stigaard Thulesen, journalist, Aarhus Universitet
Alle kan i dag få deres egen digitale assistent. Det kræver kun adgang til internettet. Og at du er villig til at bruge tjenester, der bygger på store mængder data.
Men der følger også risici med, når kunstig intelligens bliver en del af hverdagen. For AI kan bruges til langt mere end at hjælpe med indkøbslister, kodning og gode råd. Den kan også bruges til manipulation, svindel og påvirkning i stor skala. Det siger professor i datalogi Kasper Green Larsen, som forsker i teoretisk datalogi med særligt fokus på algoritmer, datastrukturer og machine learning ved Aarhus Universitet:
»Demokratiet kan komme under pres, når AI gør det lettere at sprede overbevisende indhold i stor skala. Vi mennesker bliver påvirket af det, vi ser, når vi er online, og derfor får det stor betydning, hvem der styrer teknologien, og hvad den bruges til,« forklarer professoren.
AI trænes med straf og belønning
Kunstig intelligens bygger på matematiske modeller, der kan lære at finde mønstre i store mængder data. Mange AI-systemer er bygget op omkring kunstige neurale netværk, som er inspireret af den måde, nerveceller forbindes på i hjernen. Systemerne tænker ikke som mennesker, men de kan lære at genkende mønstre og give svar, der i mange tilfælde virker imponerende præcise.
Når en AI trænes, bliver den fodret med meget store mængder data. Undervejs får systemet feedback på, om svarene bevæger sig i den rigtige eller den forkerte retning. Man kan beskrive det som en form for straf og belønning: Gode svar bliver belønnet, og dårlige svar fører til justeringer. På den måde bliver modellen gradvist bedre til sin opgave.
For eksempel kan en AI trænes til at se forskel på en kat og en croissant. Den får vist enorme mængder billeder og får igen og igen besked på, om svaret var rigtigt eller forkert. Efter mange justeringer bliver systemet bedre til at genkende de mønstre, der kendetegner en kat, også når lys, vinkel eller billedkvalitet varierer.
»Det er et kæmpe arbejde at træne en AI. Det er ikke bare et spørgsmål om nogle få eksempler eller lidt feedback. Systemerne skal lære mønstre på tværs af enorme datamængder, og det kræver både tid, regnekraft og meget store investeringer,« siger Kasper Green Larsen.
Forskningen i kunstig intelligens rummer samtidig stadig store åbne spørgsmål. Moderne AI virker ofte meget godt i praksis, men det kan være svært at forklare præcist, hvorfor en model når frem til en bestemt vurdering i det enkelte tilfælde. Det gælder også systemer som ansigtsgenkendelse. Man kender principperne bag modellen, men i praksis er den så kompleks, at vejen frem til et bestemt svar kan være svær at følge trin for trin. Meget store mængder beregninger spiller sammen på én gang, og derfor er detaljerne ikke altid gennemsigtige.

Figuren illustrerer et “neuralt” netværk, som alle generelle AI-modeller grundlæggende er baseret på. Netværkene kan have forskellige størrelser og arkitektur, men basalt set er de opbygget af forbundne informations-processerende enheder kaldet “neuroner”.
En matematisk model for en neuron afgør styrken af det signal, der sendes videre. Ligesom i hjernen kan forbindelsen mellem to neuroner være svag eller stærk (udtrykt ved forskellige vægte “w1-w3”). Når netværket trænes, går det ud på at justere vægtene mellem forbindelserne.
Mønstre i data kan styrke sikkerheden
Kunstig intelligens udvikler ikke sine egne mål. Den arbejder ud fra de mønstre og regler, som mennesker har bygget og trænet den med. Derfor opstår problemer som datalæk, svindel eller manipulation heller ikke af sig selv. De opstår, når systemer er dårligt sikret, eller når mennesker bevidst forsøger at udnytte dem.
Når vi bruger en AI-tjeneste, deler vi ofte data med virksomheden bag systemet. Hvor meget der gemmes, og hvad det bruges til, afhænger af den konkrete tjeneste, dens indstillinger og dens vilkår. Derfor er det vigtigt at tænke sig om, før man skriver fortrolige eller følsomme oplysninger ind i et AI-system.
»Når vi bruger AI, er der altid et spørgsmål om tillid. Brugerne skal kunne stole på, at deres data bliver behandlet ordentligt og beskyttet godt nok,« siger Kasper Green Larsen.
Der findes allerede eksempler på, at angribere har forsøgt at få modeller eller AI-systemer til at afsløre oplysninger, de ikke burde give adgang til. Derfor arbejder virksomheder og forskere intensivt med at gøre systemerne mere robuste. Samtidig bruges AI i stigende grad til at styrke cybersikkerheden.
AI er nemlig god til at finde mønstre i store datamængder. En model kan for eksempel trænes på tidligere svindelsager, mistænkelige transaktioner eller phishing-mails. Med tiden lærer systemet, hvilke træk der går igen, og hvilke hændelser der skiller sig ud. Dermed kan AI bruges til at opdage usædvanlig adfærd og advare hurtigere, end et menneske alene ville kunne gøre.
På samme måde kan AI bruges til at opdage svindel ved at lære forskellen på det typiske og det atypiske. Når systemet først har set eksempler nok, bliver det bedre til at pege på de tilfælde, der fortjener en ekstra kontrol.

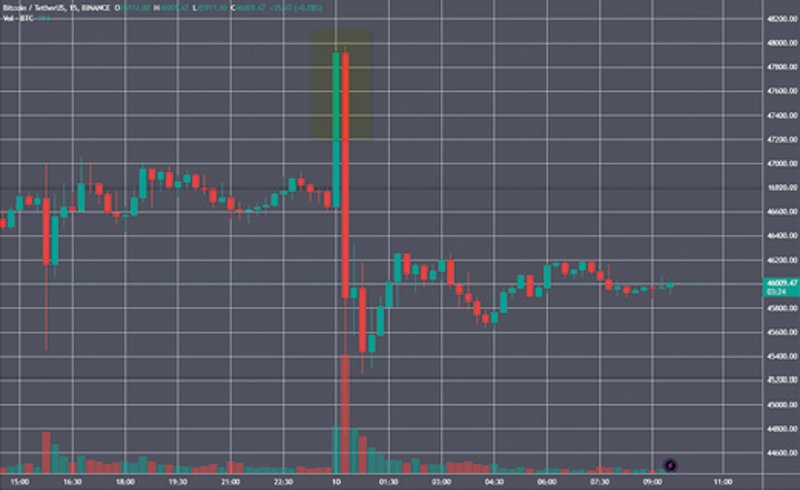
Den 9. januar 2024 blev der lagt et falsk opslag ud på den amerikanske børstilsyns-myndighed SEC’s konto på X, som annoncerede, at SEC ville godkende såkaldte bitcoin-ETF’er (ETF = Exchange-Traded Funds). Det var en blåstempling af kryptovaluta som et sikkert investeringsprodukt. Kursen på bitcoins steg derefter skarpt fra omkring 46.000 dollars til 48.000 dollars, men faldt brat igen, da SEC dementerede nyheden som et falsum. Kilde: forklog.com
Kunstig intelligens som våben
Danske it-virksomheder oplever allerede, at kunstig intelligens kan være en stor hjælp. AI kan skrive tekst, analysere information og hjælpe med at producere kode. Derfor kan teknologien effektivisere arbejdet mærkbart.
Der er heller ingen tvivl om, at AI kan være en nyttig assistent i hverdagen for mange danskere. Den kan hjælpe med alt fra indkøbslister og træningsplaner til idéer, opsummeringer og praktiske råd. Men AI-systemer kan også påvirkes af de data, de læser og arbejder med. Hvis informationen er forkert, manipuleret eller plantet med vilje, kan det få betydning for kvaliteten af de svar, systemet giver.
Et nyere eksempel kom i januar 2024, da den amerikanske børstilsynsmyndighed SEC’s konto på X blev hacket, og der blev lagt et falsk opslag ud om godkendelse af bitcoin-ETF’er. Meldingen fik kortvarigt bitcoin-prisen til at stige, før den blev dementeret. Episoden viste, hvor hurtigt markeder kan reagere, når en kilde, der fremstår troværdig, bliver manipuleret. I et marked, hvor en del handel i dag foretages automatisk af computerstyrede systemer og AI, illustrerer sagen også, hvor sårbare digitale markeder kan være over for falsk information.
»Vi ser mere og mere dataforgiftning. Det er en form for angreb, hvor man forsøger at påvirke de data, et AI-system lærer af eller søger information i. Hvis man kan manipulere de data, systemet bygger på, kan man også påvirke resultatet,« forklarer Kasper Green Larsen.
På samme måde kan AI bruges offensivt af cyberkriminelle. Teknologien kan hjælpe med at skrive mere overbevisende phishing-mails, tilpasse beskeder til bestemte personer og automatisere dele af et angreb. Dermed kan en angriber arbejde hurtigere, bredere og mere overbevisende end tidligere.
»AI bliver i stigende grad et mål i sig selv, og når nogen kan påvirke systemet eller de data, det bygger på, kan teknologien også bruges som et våben,« siger professoren.
Samfundets akilleshæl
AI kan ikke noget, den ikke er blevet trænet til af mennesker. Menneskers valg sætter rammerne. Derfor rummer teknologien den samme dobbelthed som mange andre stærke værktøjer: Den kan bruges til noget nyttigt, og den kan bruges til skade.
»Vi skal ikke stole blindt på kunstig intelligens. Vi bliver nødt til at være kritiske over for de svar, vi får fra AI, og over for det indhold vi møder, når vi bruger internettet,« mener Kasper Green Larsen.
Det ses blandt andet indenfor phishing, hvor it-kriminelle forsøger at lokke personlige oplysninger ud af mennesker gennem falske mails, beskeder eller hjemmesider. Beskederne kan ligne noget fra for eksempel en bank, en offentlig myndighed eller en velkendt virksomhed.
Kvaliteten af phishing er steget med AI, fordi systemerne kan skrive hurtigere, mere flydende og mere troværdigt end mange mennesker. Samtidig kan teknologien bruges til at tilpasse indholdet til den enkelte modtager. Det gør svindlen sværere at gennemskue.
»Stort set al nyttig teknologi, mennesket har udviklet, kan også misbruges. Sådan er det med computere, internettet og nu også AI. Det ændrer ikke ved, at teknologien kan skabe meget stor værdi, hvis vi bruger den ansvarligt.
Derfor er min holdning ikke, at vi skal være bange for AI, men at vi skal være bevidste om både mulighederne og risiciene – og sørge for at håndtere dem ordentligt,« slår professoren fast. ♦
AI-svindel i vækst
AI-svindel i vækst
Der findes umiddelbart ikke offentligt tilgængelige, globale og verificerede tal for antallet af tilfælde af svindel baseret på AI. Men ifølge rapporter fra for eksempel Sift (der er en virksomhed, der selv sælger ydelser baseret på at bruge maskinlæring til at bekæmpe digital misbrug) er AI-svindel i kraftig vækst – mere end 60 % fra 2024-2025 målt på antallet af ofre. En så kraftig stigning på ét år er angiveligt usædvanlig høj for kriminalitetsformer og antyder, at der er tale om et strukturelt skift drevet af generativ AI.
Kilde: Sift Digital Trust Index (Q2 2025)
Se artiklen: Cybersikkerhed: Internettets fundament som pdf
Om Kasper Green Larsen

Kasper Green Larsen er professor i datalogi ved Aarhus Universitet.
Kaspers forsker i teoretisk datalogi med særligt fokus på algoritmer, datastrukturer og machine learning.
Aktuelt er Kasper Green Larsen leder af et Sapere Aude Research Leader Grant fra Danmarks Frie Forskningsfond. Projektet er baseret på at anvende teknikker udviklet indenfor datastrukturer til at forbedre machine learning og kryptografiske værktøjer. En del af Kaspers forskning handler om at mindske risikoen for misbrug og gøre AI-systemer mere sikre og pålidelige.
larsen@cs.au.dk
Intropakke
Intropakke
Tilbud til nye abonnenter:
Bestil en intropakke med otte helt nye numre plus abonnement i et år (6 numre) for kun 354,- kr. inkl. porto & ekspedition. Bestil via: abonnementssiden.